Met het robots.txt-bestand kun je zoekmachines ervan weerhouden om bepaalde bestanden, mappen en pagina’s te bezoeken. Doordat het robots.txt-bestand een grote impact kan hebben op je aanwezigheid in zoekmachines, is het belangrijk dat je weet wat je doet als je dit bestand bewerkt.
In onze artikelen en op onze pagina's staan affiliate links. Wanneer je via één van deze links een aankoop doet, ontvangen wij een (meestal kleine) commissie van de verkoper. Wij geven altijd onze eerlijke mening over producten. Klik hier voor meer informatie.
In dit artikel vertel ik je dan ook precies wat je met het robots.txt-bestand moet doen. Voor de zekerheid vertel ik je ook maar meteen wat je absoluut niet moet doen ;-).
Inhoud
Wat is het robots.txt-bestand?
Het robots.txt-bestand is een tekstbestand dat je als webmaster kunt uploaden om instructies te geven aan “robots”. Het gaat hier dan om “robots” van zoekmachines. Deze worden ook wel spiders of crawlers genoemd. Dit zijn “bots” die jouw website scannen en “lezen” om ze vervolgens al dan niet toe te voegen aan de “index” van de zoekmachine.
Divi theme & Divi Builder
Bij Elegant Themes ontvang je meer dan
85 premium WordPress themes (waaronder Divi!) voor maar 89 dollar!
Bekijk de themes »»
Lees meer over Divi.

Het robots-bestand maakt deel uit van het Robot Exclusion Protocol, ook wel afgekort als REP. Dit zijn webstandaarden die bepalen hoe robots het web crawlen en hoe content geïndexeerd wordt. Niet alleen het robots.txt-bestand valt onder dit protocol. Ook de noindex- en nofollow-tags vallen hieronder. Die tags bepalen of links wel of niet gevolgd moeten worden en of specifieke pagina’s geïndexeerd moeten (of mogen) worden.
Waar staat het robots.txt-bestand?
Als je website een robots.txt-bestand heeft, dan hoort deze in de “root” van je website te staan. Bij onze website is dat dus de locatie wplounge.nl/robots.txt.
De meeste WordPress-websites hebben een standaard robots.txt-bestand dat er zo uit ziet:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Hierin worden robots en zoekmachine-spiders geweerd uit de WordPress admin-omgeving, met uitzondering van het admin-ajax.php-bestand.
Hoe ziet een robots.txt-bestand eruit?
Een robots.txt-bestand is een tekstbestand met de extensie TXT. Hoe de inhoud van dit bestand eruit ziet verschilt heel erg per website. De inhoud van het robots-bestand is als volgt opgebouwd:
User-agent: [naam van de user-agent] Disallow: [URL string die niet gecrawld mag worden]
De regel die begint met “user-agent:” geeft aan welke robot deze regel betreft. Je kunt hier ook een sterretje (*) invullen om aan te geven dat het alle robots betreft. De tweede regel (die begint met “Disallow:”) geeft aan welke URL’s er door deze robot niet gecrawld mogen worden.
Je kunt in één robots.txt-bestand ook meerdere URL’s opgeven voor één specifieke robot of spider. Een voorbeeld kun je zien in het robots.txt-bestand van Apple.com:

In het voorbeeld van Apple.com wordt de user-agent met de naam “Baiduspider” geblokkeerd voor verschillende URL’s.
Voorbeelden
Ik geef een aantal voorbeelden van robots.txt-bestanden om je een idee te geven wat de verschillende soorten “codes” voor invloed hebben op hoe zoekmachines en andere spiders/robots je website bezoeken.
1: Alle content blokkeren voor robots
Het volgende stukje code zegt tegen alle robots (sterretje) dat alle content niet gecrawld mag worden. De “slash” (/) geeft aan dat alle URL’s die beginnen met “/” niet gecrawld mogen worden.
User-agent: * Disallow: /
Als je dit in je robots.txt-bestand zet is de kans groot dat je website op een gegeven moment uit Google zal verdwijnen.
2: Alle content toestaan voor (alle) robots
De volgende code doet het tegenovergestelde: alle content mag geïndexeerd worden door alle robots.
User-agent: * Disallow:
Doordat er na “disallow” niets staat, zullen robots dit interpreteren als: alle content die ik kan vinden mag gecrawld worden.
3: Een specifieke robot blokkeren uit een specifieke folder of pagina
De volgende code in je robots.txt-bestand blokkeert de robot met de naam “Googlebot” om de folder example-subfolder te crawlen.
User-agent: Googlebot Disallow: /example-subfolder/
In dit voorbeeld zeg je dus eigenlijk tegen de Google-robot: je mag niet in deze specifieke folder kijken.
Hoe ziet een goed robots.txt-bestand voor WordPress eruit?
Als je een WordPress-website hebt, dan vraag je je inmiddels waarschijnlijk af: hoe moet mijn robots.txt-bestand er dan uitzien? Dat is een goede vraag, want de meningen zijn verdeeld. We lieten hierboven al zien dat het standaard robots.txt-bestand van WordPress alléén de wp-admin folder blokkeert. De SEO-specialisten van Yoast denken ze daar echter anders over.
Yoast geeft aan dat het helemaal niet nodig is om je wp-admin folder te blokkeren. Dit heeft te maken met het feit dat de admin-folder al meta-tags heeft die robots vertellen dat deze folder niet geïndexeerd hoeft te worden.
Zolang je robots.txt-bestand er dus niet uitziet zoals bij voorbeeld 1, hoef je je dus niet al te veel zorgen te maken.
Testen: Fetchen als Google
 Het belangrijkste is om te testen of Google je pagina’s goed kan crawlen. Hiervoor zit gelukkig een handige feature in Google Search Console. Door je website toe te voegen aan Search Console, kun je allerlei handige informatie achterhalen over je website en hoe Google je website ziet. Doe er je voordeel mee, zou ik zeggen.
Het belangrijkste is om te testen of Google je pagina’s goed kan crawlen. Hiervoor zit gelukkig een handige feature in Google Search Console. Door je website toe te voegen aan Search Console, kun je allerlei handige informatie achterhalen over je website en hoe Google je website ziet. Doe er je voordeel mee, zou ik zeggen.
Eén van de handigste features van Google Search Console is Fetchen als Google (of in het Engels “Fetch as Google”). Deze vind je onder “Crawlen”. Hier kun je een URL van je website laten crawlen door Google. Onze grote vriend Google laat je vervolgens zien hoe jouw pagina er volgens Google uitziet.
Wij hebben ons artikel van gisteren (WordPress “Syntax error” oplossen) door de “Fetchen als Google”-tool gehaald en kregen het volgende resultaat:
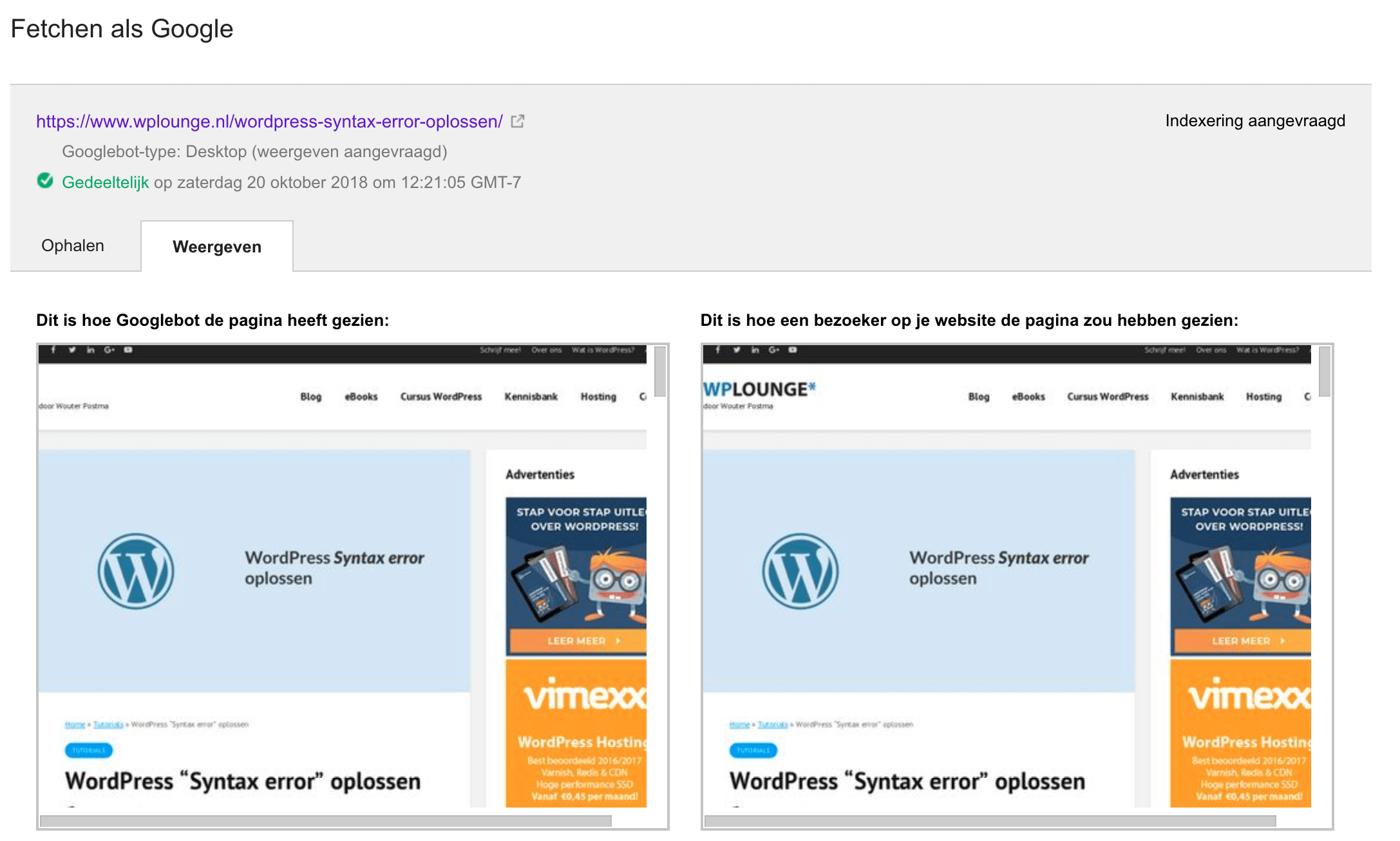
Google geeft bovenin de URL van je pagina aan en daarnaast laat Google zien of de Googlebot je pagina “gedeeltelijk” of “volledig” heeft kunnen crawlen. In het voorbeeld hierboven hebben we een paar URL’s geblokkeerd met robots.txt zodat het resultaat “gedeeltelijk” zou zijn.
Het belangrijkste onderdeel van dit rapport is het verschil tussen “Dit is hoe Googlebot de pagina heeft gezien” (links) en “Dit is hoe een bezoeker op je website de pagina zou hebben gezien” (rechts). Als hier hele grote verschillen tussen zouden zitten, dan doet je website iets fout: Google wil graag zien wat een bezoeker ook zou zien. Zorg er daarom voor dat JavaScript- en CSS-bestanden goed kunnen worden gecrawld, want Google kijkt tegenwoordig overal naar. Zo kan Google de algehele “experience” van je website beter beoordelen en dus beter bepalen welke website een hogere kwaliteit heeft.
Het robots.txt-bestand bewerken
 Wil je na het lezen van dit artikel het robots.txt-bestand van je WordPress-website aanpassen? Dat kan! Je kunt natuurlijk via FTP inloggen en het bestand handmatig aanpassen, maar als jouw website (net als WPLounge.nl) één van de meer dan vijf miljoen websites is die de Yoast SEO-plugin gebruiken, dan kan het ook makkelijker!
Wil je na het lezen van dit artikel het robots.txt-bestand van je WordPress-website aanpassen? Dat kan! Je kunt natuurlijk via FTP inloggen en het bestand handmatig aanpassen, maar als jouw website (net als WPLounge.nl) één van de meer dan vijf miljoen websites is die de Yoast SEO-plugin gebruiken, dan kan het ook makkelijker!
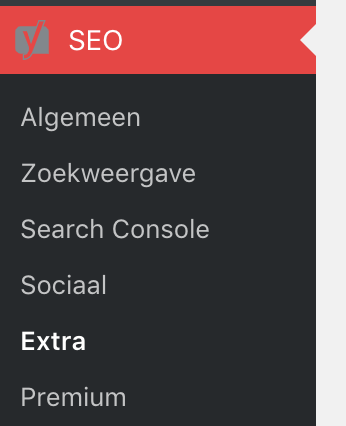
Ga naar het “SEO”-menu in WordPress en kies vervolgens voor “Extra”. Hier vind je de optie “Bestandsbewerker”:

Klik op de link om de bestandsbewerker te openen. Hier kun je je robots.txt-bestand direct aanpassen. Tenminste, als deze schrijfbaar is. En denk eraan: test of je geen fouten hebt gemaakt door een aantal willekeurige pagina’s van je website door de “Fetchen als Google”-tool te halen! Zo kom je er direct achter of je een fout hebt gemaakt die desastreus kan zijn voor je zichtbaarheid in de zoekmachines.
Conclusie
Het robots.txt-bestand is een krachtige tool om robots te weren van bepaalde onderdelen op je website. Als je wilt dat je website gewoon goed geïndexeerd wordt dan is het eigenlijk het beste om van het robots-bestand af te blijven, dan kun je ook niets fout doen ;-).
Vermoed je toch dat er iets mis is met je robots-bestand? Ga dan naar jouwwebsite.nl/robots.txt en check aan de hand van de voorbeelden hierboven of er wellicht iets mis is. Of test het door de tool in Google Search Console te gebruiken. Kom je er niet uit? Neem dan gerust contact met ons op!





Reageer